See VIVID in action in this Video Demo.
The lengthy monologue-style online lectures cause learners to lose engagement easily. Designing lectures in a “vicarious dialogue” format can foster learners’ cognitive activities more than monologue-style. However, designing online lectures in a dialogue style catered to the diverse needs of learners is laborious for instructors. We conducted a design workshop with eight educational experts and seven instructors to present key guidelines and the potential use of large language models (LLM) to transform a monologue lecture script into pedagogically meaningful dialogue. Applying these design guidelines, we created VIVID which allows instructors to collaborate with LLMs to design, evaluate, and modify pedagogical dialogues. In a within-subjects study with instructors (N=12), we show that VIVID helped instructors select and revise dialogues efficiently, thereby supporting the authoring of quality dialogues. Our findings demonstrate the potential of LLMs to assist instructors with creating high-quality educational dialogues across various learning stages.
Teachers and VIVID collaboratively design dialogues through three stages: 1. Initial Generation, 2. Comparison & Selection, and 3. Refinement.
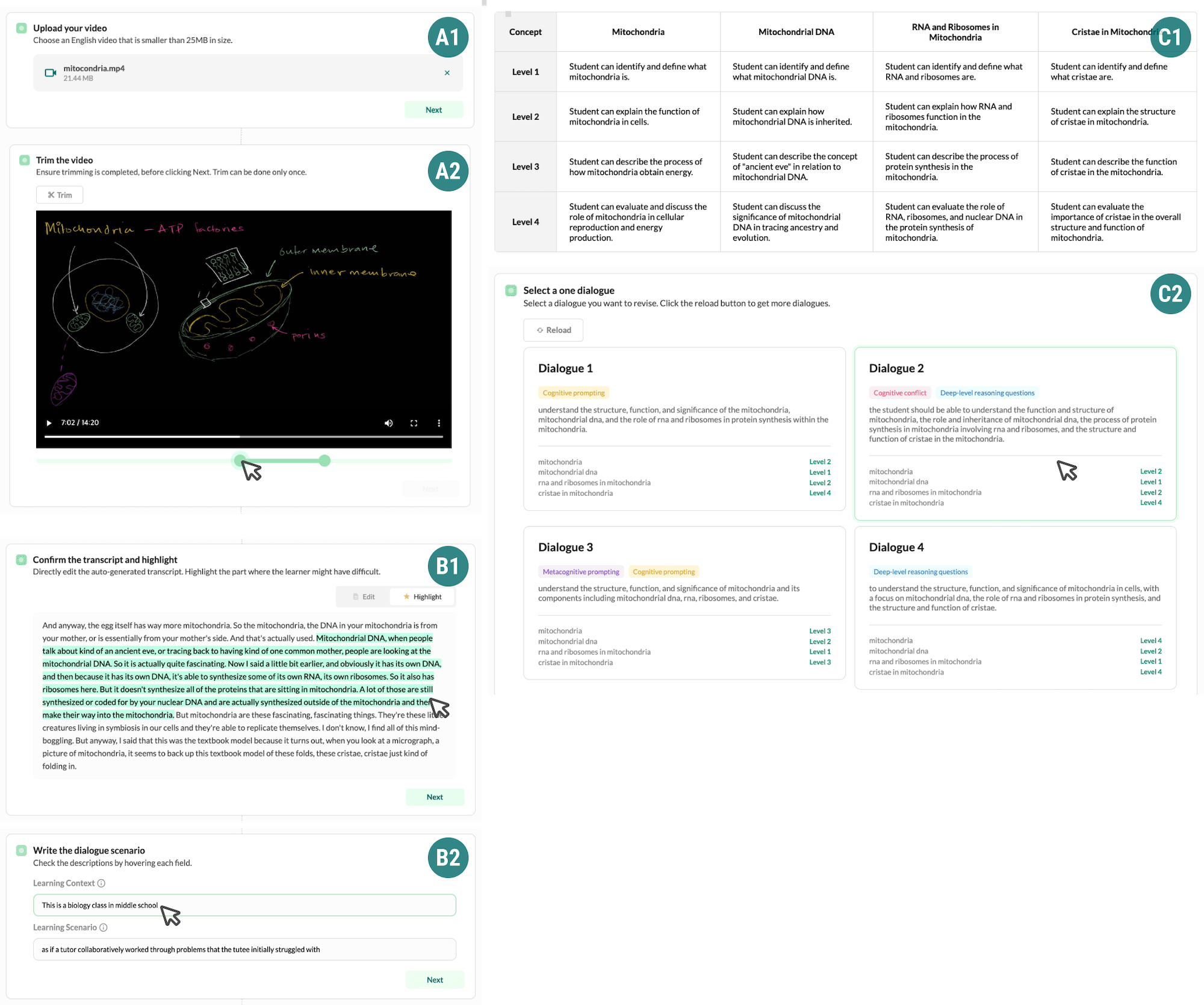
In the Initial Generation stage, user uploads lecture video (A1) and trims a video section to convert (A2). User uses the highlighting feature by selecting a part of the video transcript (B1), where vicarious learners may face difficulty understanding. User then writes down the learning context and the scenario of dialogue that they want to depict in final dialogue (B2). In the Comparison and Selection phase, VIVID shows a rubric table of learners’ understanding level regarding key concepts stated in the transcript (C1). VIVID presents generated dialogues in the form of dialogue cards comprising of core information from each dialogue (C2).
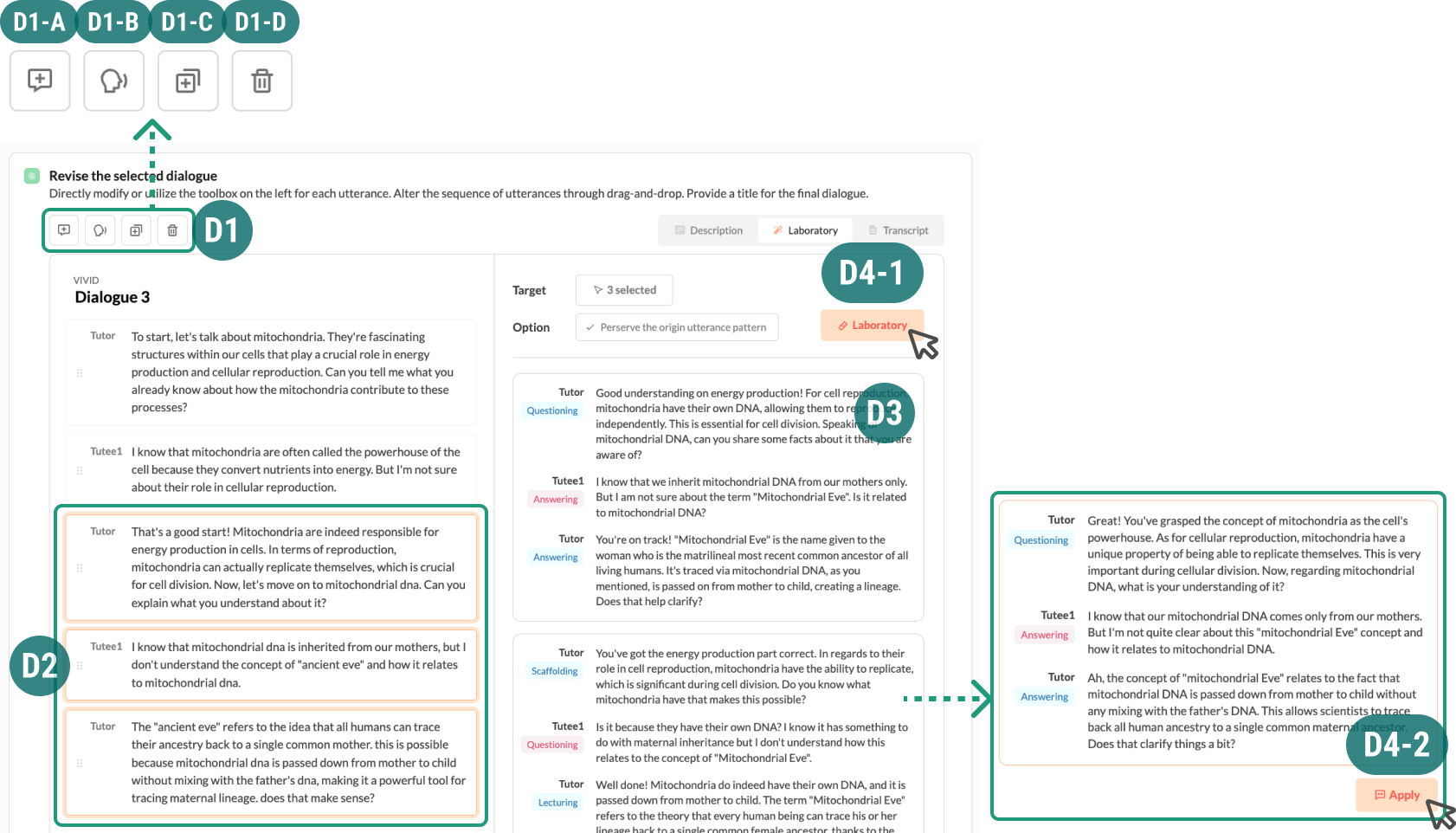
In the Refinement stage, user can edit each utterance content directly or using basic editing tools (D1). User can use laboratory feature by selecting consecutive utterances (D2) and clicking Laboratory button (D4-1). VIVID suggests four variations of sub-dialogues as a result (D3). User can replace the original utterances with a variation by clicking Apply button (D4-2).
The dialogue examples are the dialogue generated using VIVID’s Initial Generation pipeline and the dialogue generated using the Baseline’s Initial Generation pipeline. The lecture utilized is from Khan Academy’s physic lecture.

This is the transcript used to generate the dialogue. The authors highlighted the green part as potentially difficult for vicarious learners to understand when generating dialogue data.

This is a dialogue generated using the Initial Generation pipeline of Baseline.

This is a dialogue generated using the Initial Generation pipeline of VIVID.
@misc{choi2024vivid,
title={VIVID: Human-AI Collaborative Authoring of Vicarious Dialogues from Lecture Videos},
author={Seulgi Choi and Hyewon Lee and Yoonjoo Lee and Juho Kim},
year={2024},
eprint={2403.09168},
archivePrefix={arXiv},
primaryClass={cs.HC}
}
![]()
![]()



